Back to Resources
RAG, Fine-Tuning, or Both? Optimizing Enterprise AI for Accuracy and Cost

Key takeaways
- RAG helps produce up-to-date responses from supplied documentation, but limitations in cost, speed, and flexibility make it an incomplete solution for most enterprise needs.
- Fine-tuning allows more LLM customization for specific tasks and use cases, but the process requires heavy upfront investments in talent, data management, and infrastructure.
- Combining fine-tuning and RAG can often lead to optimal model outcomes, but enterprises still face challenges of cost and complexity in AI customization.
- SeekrFlow™ accelerates the model fine-tuning process and reduces the downstream costs of RAG by handling data alignment and preparation for you.
For enterprises to unlock real value from AI, models need to produce accurate responses based on specific company data. Whether it’s a chatbot that answers customer questions about a retailer’s return policy or helps a financial institution’s customers understand available loan options, it’s crucial that the LLM gets the answer right.
Achieving this level of LLM customization typically involves two techniques: RAG (Retrieval Augmented Generation) and fine-tuning. Each technique has its strengths and challenges in cost, time, data requirements, and performance. Depending on your use case, you may find that one—or a combination of the two—is more effective.
In this post, we’ll unpack the differences between RAG and fine-tuning and explore how enterprises can overcome the cost and complexity of AI customization to drive real business transformation.
Comparing RAG and fine-tuning
An overview of RAG
Some businesses choose to solely use RAG rather than fine-tuning a model. With RAG, pre-trained models fetch or ‘retrieve’ data at runtime from supplied documentation to inform accurate responses.
Benefits of RAG
- Accuracy: Guarantees that LLM responses are current and relevant, providing data on demand for dynamic use cases
- Efficiency: Allows you to update documentation and resources without retraining
- Reduced upfront costs: Avoids the initial time and expense of fine-tuning a model before deployment
Many believe that RAG is the only solution for producing specific, accurate answers. However, the RAG technique alone can present significant limitations in cost, speed, and flexibility that make it an incomplete solution for most enterprise use cases.
Costs of RAG
There are several long-term costs associated with using RAG in enterprise applications, including:
- High token costs: RAG without fine-tuning means the LLM must retrieve the information from supplied documentation for every single request, making the cost per query significant
- Data hosting: Businesses must create and maintain a database to host documents
- Ongoing evaluation: A RAG evaluation framework must be developed and maintained to monitor the performance and effectiveness of a RAG-based system
- Compute resources: For RAG to work well, it requires a large generalist model, which in turn requires a large amount of computing resources
Other limitations of RAG
- Slower speed: The retrieval process must happen for every response, which means the LLM must “read” all the provided documentation to produce an informed answer
- Complex data structure: More accurate domain-specific responses require intricate data management which can become time and cost prohibitive
- Less customization: RAG doesn’t offer the same qualitative customization of LLMs that fine-tuning does, making it less adaptable to specific enterprise use cases like medical diagnosis and treatment recommendations, legal contract drafting, or personalized financial advice
Fine-tuning
Fine-tuning, done correctly, can provide production-grade accuracy in enterprise applications by training a base model on domain-specific data. It requires the collection and processing of new datasets to train the model and enhance its knowledge in a specific area.
Benefits of fine-tuning for enterprise applications:
- Production-grade accuracy: Create more accurate responses to specialized tasks that require domain-specific knowledge
- Lower latency: Produce faster response times in real-time applications
- More customization: Customize qualitative aspects of the LLM like writing style and tone
- Reliability: Improve the reliability of desired outputs
The catch: customizing an LLM on your own data is no small feat. The traditional fine-tuning process presents major challenges in cost, time, and infrastructure.
Challenges in traditional fine-tuning
- High talent costs: Significant upfront costs are required to recruit data and ML talent to effectively fine-tune an enterprise-ready model
- Time-consuming: Collecting and processing vast amounts of data slows down innovation
- Infrastructure demands: Requires substantial infrastructure for training and hosting the custom LLM
Should you combine fine-tuning and RAG?
Depending on your use case, the best path to AI value may be to customize LLMs with a combination of RAG and fine-tuning. Fine-tuning creates a specialized LLM that better understands the specific task while RAG ensures that responses are accurate and up to date based on the latest documentation.
Let’s compare the LLM to a medical doctor. Doctors study for years in medical school to become experts on the topic of medicine. This level of training is required for them to be considered qualified to perform their job. In their practice, they also need access to up-to-date medical research and disease references to accurately diagnose and treat their patients.
Fine-tuning is like medical school. It creates faster, more knowledgeable LLMs that can adapt to a wider range of industry-specific needs. Combining the fine-tuning process with the RAG approach gives your LLM access to the latest information for more accurate and reliable answers.
Taking a hybrid approach: Reducing token costs by 60% with SeekrFlow
Whether you choose RAG, fine-tuning, or a combination, the massive data and infrastructure requirements of building custom AI can quickly decrease the value of its implementation. Overcoming these challenges requires tackling your data problem from the start.
That’s where Seekr can help. Our end-to-end AI development platform, SeekrFlow, helps you accelerate your fine-tuning process and reduce the downstream costs of RAG by handling data alignment and preparation for you.
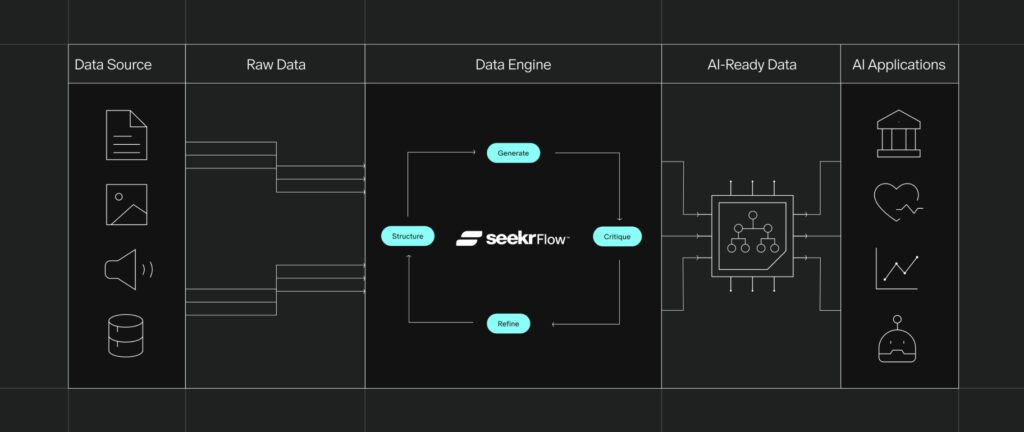
Data preparation typically involves gathering, labeling, normalizing and formatting data—a time and resource intensive process. It also relies on humans to catch and label mistakes, which can lead to unpredictable or biased outcomes.
With SeekrFlow’s autonomous data creation workflow, you can align a generalist model to the high-level industry principles, values, or regulations of a specific domain with minimal human intervention. The result is a fine-tuned specialist model that adheres to these principles and boosts the effectiveness of RAG at runtime.
This unique approach streamlines the model customization process so businesses can realize the true value of AI faster.



Accelerate your path to AI impact
Book a consultation with an AI expert. We’re here to help you speed up your time to AI ROI.
Request a demo
