Inference without compromise
Deploy models on the infrastructure you choose, with predictable performance, reliable scaling, and full control.
Scale inference without limits
Start with hosted base models or move to dedicated endpoints for more control. Either way, Seekr ensures performance, scalability, and enterprise-ready reliability.
Performance control
Tune throughput and latency by configuring endpoints to match your application’s needs.
Instant access
Run hosted base models with auto-scaling, no manual setup required.
Tailored for workloads
Configure inference to match domain-specific and application needs.
Hardware freedom
Run on an array of hardware options including NVIDIA and AMD.
Performance insight
Monitor latency, throughput, and reliability across endpoints.
Enterprise-ready
Dedicated resources provide compliance and isolation at scale.
From selection to scale
Streamline the entire inference lifecycle, delivering consistent speed and resilient capacity for enterprise workloads.
Model selection
Choose the right starting point
Choose from our library of open-source models, including chat, instruct, vision, and domain-specialized options. Whether you need a compact model for cost-efficient tasks or a larger model for advanced reasoning, Seekr helps you align model choice with task complexity, domain requirements, and performance goals.
Model customization
Tailor models to your domain
Enhance base models with fine-tuning (Instruction, context-grounded, GRPO), extend capabilities with vector stores for Retrieval-Augmented Generation (RAG), or connect to SeekrFlow Agents for more complex workflows. This stage ensures the model is domain-specific, accurate, and enterprise-ready.
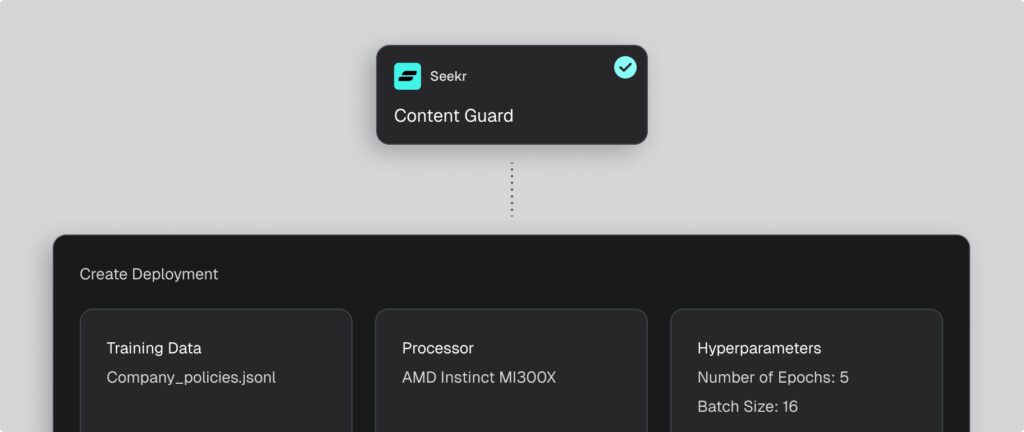
Dedicated deployment
Run on dedicated endpoints
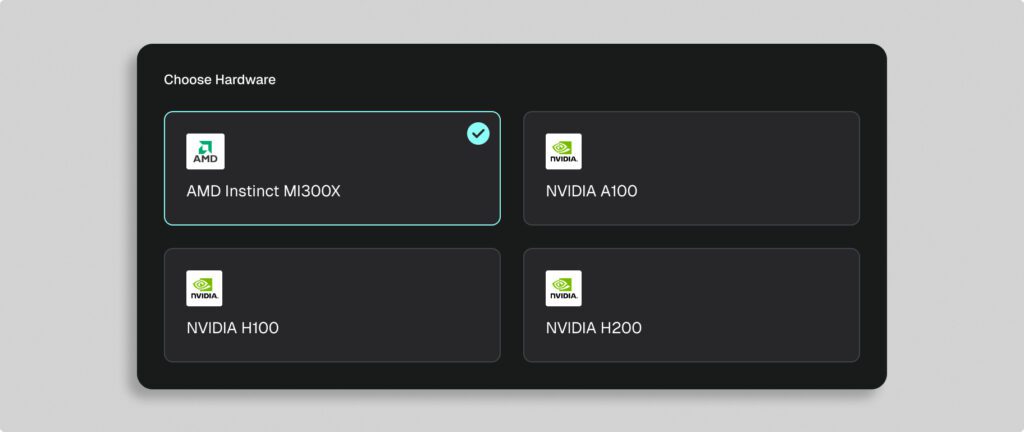
Launch your customized model on a dedicated endpoint with reserved capacity. Choose from an array of hardware options—including NVIDIA A100/H100/H200 or AMD MI300X—to optimize for throughput, latency, and cost-performance balance. Dedicated endpoints deliver predictable speed, resilient capacity, and freedom from noisy-neighbor effects common in serverless setups.
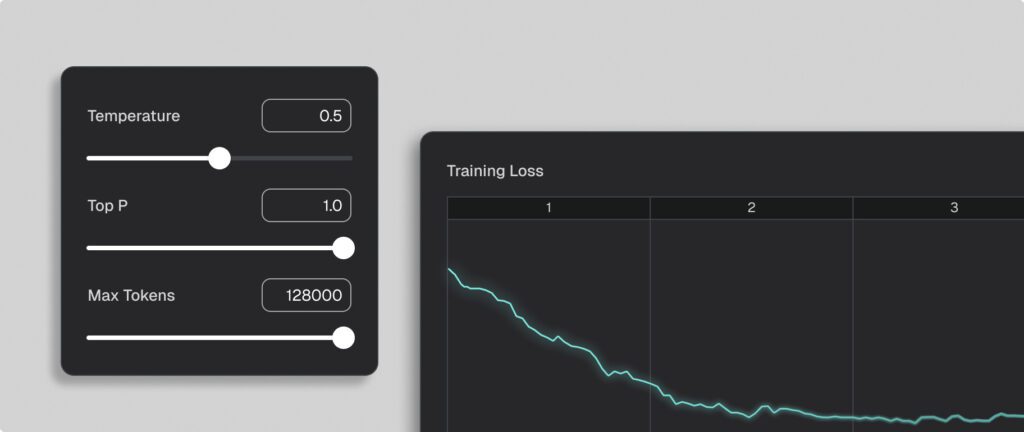
Monitoring & validation
Ensure ongoing reliability
Track inference performance with detailed metrics on latency, throughput, and reliability. Seekr gives you full visibility to debug issues, fine-tune parameters, and confirm models are production-ready.
Secure by design
With Seekr, your data remains yours. We never use it to train other models and give you full control to install our platform wherever your data resides. Our SOC 2 Type II certification ensures best-in-class security, featuring fine-grained access controls and the flexibility to run on your preferred cloud or hardware.
Learn more

0x
more accurate model responses
0x
more relevance in responses
0x
faster data preparation vs others
0%
cheaper costs vs traditional approaches
0
minutes or less to build a production-grade LLM

Top enterprise and government leaders trust Seekr



“Seekr is setting a high bar for performant and efficient end-to-end AI development with its SeekrFlow platform, powered by AMD Instinct MI300X GPUs. We’re proud to work with Seekr as they showcase what’s possible using AMD Instinct GPUs on OCI’s AI enterprise infrastructure.”
Negin Oliver
CVP, Business Development – AI and Cloud at AMD



FAQs
What is a dedicated endpoint?
A dedicated endpoint reserves hardware for your model, ensuring predictable latency and consistent throughput.
How are dedicated endpoints different from serverless inference?
Serverless inference shares resources; dedicated endpoints guarantee performance by isolating your workloads.
How do I choose model size?
Smaller models are faster and cheaper; larger models offer better reasoning. Match size to your task complexity.
What about memory requirements?
Larger models and batch sizes require more memory. Dedicated hardware ensures capacity without resource contention.
Can I monitor inference metrics?
Yes. Latency and throughput are tracked to validate model performance in production.
How do I handle spiky traffic?
Dedicated endpoints maintain reserved capacity, so sudden traffic spikes don’t affect performance or reliability.
Accelerate your path to AI impact
Book a consultation with an AI expert. We’re here to help you speed up your time to AI ROI.
Request a demo
