Custom AI built for your domain
From training on proprietary knowledge to building stronger reasoning skills, SeekrFlow fine‑tuning delivers trustworthy AI that’s always enterprise-ready.
Empower models to specialize, adapt, and reason with confidence
SeekrFlow fine-tuning empowers your models with specialization, adaptability, and advanced reasoning—helping enterprises unlock accurate, compliant, and trustworthy AI across every use case.
Domain expertise
Train models on proprietary or sensitive data to capture organizational knowledge and improve task accuracy.
Compliance alignment
Ensure outputs follow regulatory and policy requirements, reducing risk in high-stakes environments.
Real-time knowledge access
Ground responses in live data sources, keeping answers current without costly retraining.
Dynamic adaptability
Maintain accuracy as documents, regulations, or business requirements evolve.
Stronger reasoning
Enhance model logic and decision-making to solve problems with verifiable accuracy.
Confidence at scale
Deploy reasoning models that improve reliability in complex, high-stakes workflows.
Paths to smarter fine-tuning
SeekrFlow supports instruction, contextual, and reinforcement fine-tuning, covering every need from domain expertise to real-time accuracy and reasoning.
Instruction
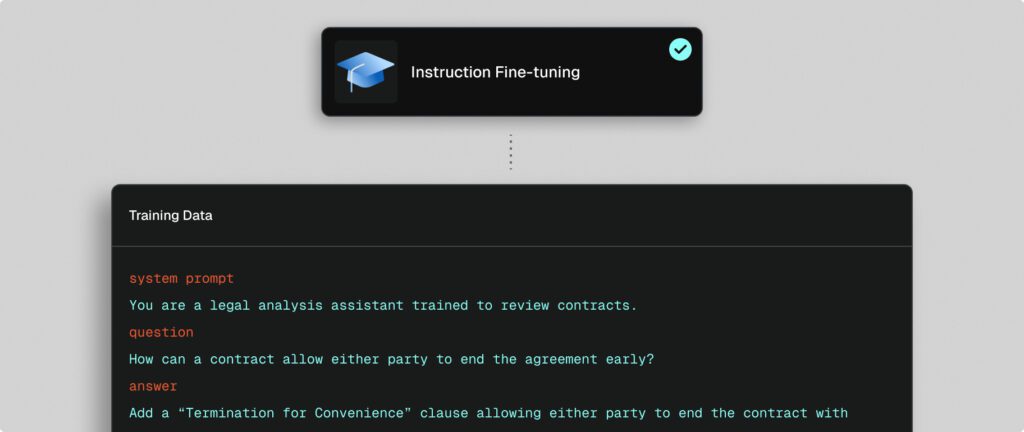
Instruction fine-tuning
Instruction fine-tuning adapts generalist models to your domain by training on curated question-and-answer (QA) pairs. With SeekrFlow, dataset creation is automated, removing manual effort and ensuring data quality. This approach embeds proprietary and sensitive knowledge directly into model parameters, while aligning outputs with compliance standards such as HIPAA or GDPR. Use it to specialize models in high-stakes areas like legal contract analysis, regulatory compliance, or domain-specific research, improving both reliability and efficiency.
Read our docs
Context-grounded
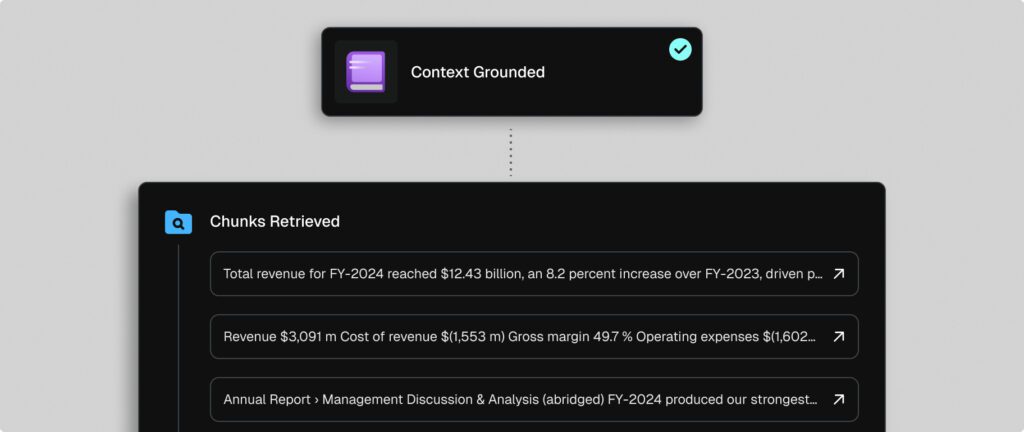
Context-grounded fine-tuning
Context-grounded fine-tuning complements traditional training by enabling models to access external knowledge bases during inference. Instead of retraining every time information changes, SeekrFlow grounds responses in verified, up-to-date data sources, ensuring outputs remain accurate as documents and regulations evolve. This flexibility is essential for industries where information shifts rapidly. With contextual fine-tuning, enterprises can strike a balance between embedded expertise and dynamic adaptability, giving teams both stability and real-time accuracy.
Read our docs
Reinforcement
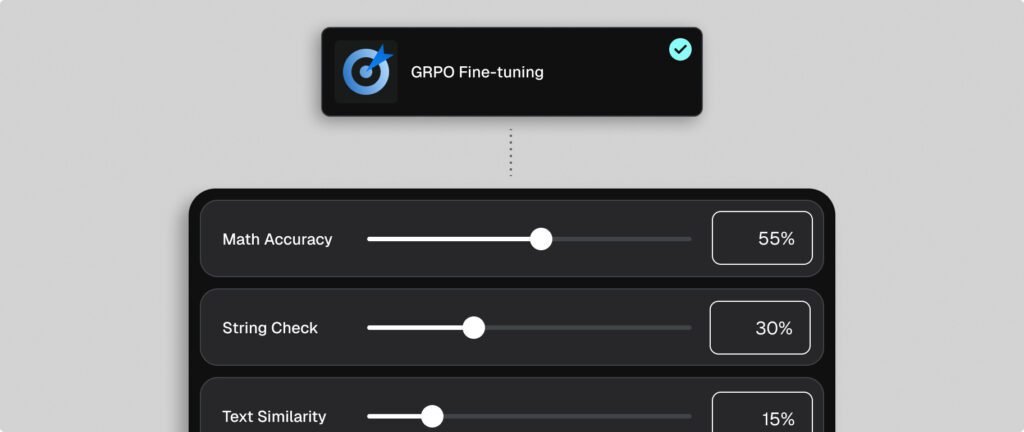
GRPO fine-tuning
Reinforcement fine-tuning with Group Relative Policy Optimization (GRPO) strengthens a model’s reasoning capabilities. SeekrFlow trains models to work through problems step by step, rewarding outcomes that match verifiable answers. This approach is powerful for domains where correctness is measurable, such as mathematical reasoning, compliance checks, or technical problem-solving. By integrating reinforcement signals with structured prompts, enterprises can develop AI that responds accurately and provides clear explanations of its reasoning, improving trust, accountability, and adoption in critical workflows.
Read our docs
Secure by design
With Seekr, your data remains yours. We never use it to train other models and give you full control to install our platform wherever your data resides. Our SOC 2 Type II certification ensures best-in-class security, featuring fine-grained access controls and the flexibility to run on your preferred cloud or hardware.
Learn more

0x
more accurate model responses
0x
more relevance in responses
0x
faster data preparation vs others
0%
cheaper costs vs traditional approaches
0
minutes or less to build a production-grade LLM

Top enterprise and government leaders trust Seekr



“Seekr is setting a high bar for performant and efficient end-to-end AI development with its SeekrFlow platform, powered by AMD Instinct MI300X GPUs. We’re proud to work with Seekr as they showcase what’s possible using AMD Instinct GPUs on OCI’s AI enterprise infrastructure.”
Negin Oliver
CVP, Business Development – AI and Cloud at AMD



FAQs
When should I use fine-tuning?
Use fine-tuning when base models lack access to proprietary, sensitive, or evolving data, or when outputs need consistent accuracy and style.
How do I monitor fine-tuning runs?
Monitor runs in a dashboard with event logs and loss/accuracy charts, so you can tweak hyperparameters and improve results quickly.
What are hyperparameters?
Configurable training settings like learning rate, batch size, and epochs that directly impact performance.
How do I set learning rate?
Start low (e.g, 0.001) and adjust based on convergence. Too high risk instability, too low may require longer training.
What is batch size in training?
The number of samples per update. Larger batches improve stability but require more memory. Smaller batches train faster.
How many epochs should I run?
Enough to converge without overfitting. Balance training time, data size, and learning stability when choosing epochs.
What is max sequence length?
Max sequence length refers to the maximum input tokens a model handles. Longer sequences capture more context but demand more compute.
Accelerate your path to AI impact
Book a consultation with an AI expert. We’re here to help you speed up your time to AI ROI.
Request a demo
