Back to Blogs
The Hallucination Tax: Why Your Best Models Are Costing You the Most

The industry is telling you hallucinations are getting better. The data agrees – for the workflows nobody runs in production.
Last May, Anthropic’s CEO Dario Amodei stood in front of a press room and said today’s frontier models “probably hallucinate less than humans.” Vectara’s hallucination leaderboard backs him up: top models now score under 1% on grounded summarization tasks. Headlines have followed. The story is that the hallucination problem is solved or close to it.
Pull your AI usage logs. The story doesn’t match.
In the workflows your enterprise actually runs (agentic chains, reasoning over broad retrieval, high-stakes domain queries), hallucinations are not decreasing. They are rising sharply. And in a per-token economy, every hallucinated answer carries the same line-item cost as a correct one. Often a higher cost, because hallucinated reasoning chains run longer before they land.
This is the hallucination tax. And it’s getting more expensive.
The aggregate is real. The conditional is the opposite.
The Vectara number is honest. It measures one specific task: summarize a document the model has been handed. In that condition, the best models are remarkably good.
But, that’s not your condition.
When OpenAI shipped o3 and o4-mini (its reasoning models, the ones enterprises are now wiring into agent stacks), its own system card disclosed something the industry has not absorbed. On PersonQA, OpenAI’s internal hallucination benchmark, o3 hallucinated on 33% of prompts. o4-mini hallucinated on 48%. The predecessor o1 hallucinated on 16%. The newer reasoning models doubled and tripled the rate of their predecessors. OpenAI’s technical report said only that “more research is needed.”
The pattern is now a research finding. An ICLR 2026 paper, “The Reasoning Trap,” demonstrated that training models to reason harder amplifies hallucination instead of reducing it. The mechanism is intuitive once you sit with it: a reasoning model makes more claims per response, so it makes more correct claims AND more wrong ones. Chain-of-thought compounds confidence, not accuracy.
This is before you add agents.
Microsoft Research’s VeriTrail paper, published in early 2026, was direct: hallucination detection in agentic workflows requires per-step provenance because errors propagate through chains. The AgentHallu benchmark showed that a single upstream planning hallucination propagates into downstream tool calls, degrading the final answer. In legal queries, Stanford RegLab measured hallucination rates between 69% and 88%. In Q1 2026, U.S. courts levied $145,000 in sanctions against attorneys who filed AI-generated false citations – the highest quarterly total in legal history.
The conditional is the opposite of the aggregate. Hallucinations are getting worse exactly where enterprises are scaling.
Every wrong answer is on your invoice
Now the cost side.
A Deloitte CFO advisory published last month told the story of a large healthcare enterprise. Token consumption grew 8-10% month over month, hit roughly a trillion tokens over six months, and translated to more than $6 million in unplanned annualized cost before finance even had visibility into the driver. Microsoft Research found that agentic coding tasks consume 1,000x more tokens than a chat conversation, with input tokens – not output – driving the bill. Gartner has now formalized the warning: a session starting at 5,000 tokens per call can reach 200,000 tokens per call by turn 50, because context compounds and you pay for the full context on every turn.
This is the trap. The agentic shift is real. It is also a token amplifier. And it does not discriminate between correct outputs and hallucinated ones. You pay for both at the same rate.
That means every hallucination is double damage: the cost of the wrong answer (token spend, downstream rework, audit exposure, customer harm) plus the cost of the tokens that produced it. The CFO is now looking at a line item that has no accountability layer underneath it.
System-level explainability is the lever
The reflex response is to wait for a better model. Don’t.
The hallucination problem in production is overwhelmingly a retrieval problem, not a generation problem. The most-cited finding across 2025 and 2026 RAG research literature is that enterprise RAG fails at the wrong chunk, not the wrong inference. Bloated retrieval inflates every prompt before the model processes a single word of user input, then compounds on every call in an agentic workflow. The model is doing what it was asked to do. It was asked to reason over junk.
What enterprises need is not better models alone. They need visibility into every influence on every output: context, retrieval, fine-tuning data, and agent steps. Then they can choose the right correction. Sometimes that’s retrieval tuning. Sometimes source curation. Sometimes targeted retraining. Always inside their own trust boundary, where the sensitive context that would actually improve grounding can stay. Specifically:
- The ability to see what the model pulled from, at the token level, for any given output.
- The ability to score the influence of each contributing source.
- The ability to dial sources up or down, pruning what shouldn’t have been in the retrieval scope in the first place, without retraining anything.
This is what SeekrFlow is built to do. SeekrFlow surfaces the source pairs that most influenced any given response, scores their impact as High, Medium, Low, or Irrelevant, and lets operators click directly through to the document chunk that drove the answer. Confidence is exposed at the token level with color-coded scoring. Every agent run is traced. Every reasoning step, tool call, and output is logged. The operator gets a steering wheel where the rest of the market is selling self-driving cars with no view of the road.
That control changes the economics. Pruning low-value sources doesn’t just reduce hallucinations. It reduces tokens spent generating outputs grounded in noise. Both lines on the curve bend down at once.
One school of architectural thought is to build a comprehensive ontology of your enterprise – a structured semantic model the LLM queries instead of free text. That approach has real value for structured operational data, but it doesn’t reach the unstructured workflows where most hallucination actually lives, and it requires years of upfront infrastructure investment that most enterprises can’t afford to put ahead of getting AI into production.
Three risks. All three compound. All three respond to the same lever.
The chart Seekr has used to describe enterprise AI risk shows three risks across Adoption, Production, and Scale: hallucinations declining, judgment and cost compounding exponentially. That picture was true at the model-output layer. At the workflow layer, where enterprises actually live, all three compound. And same complexity drives all three.
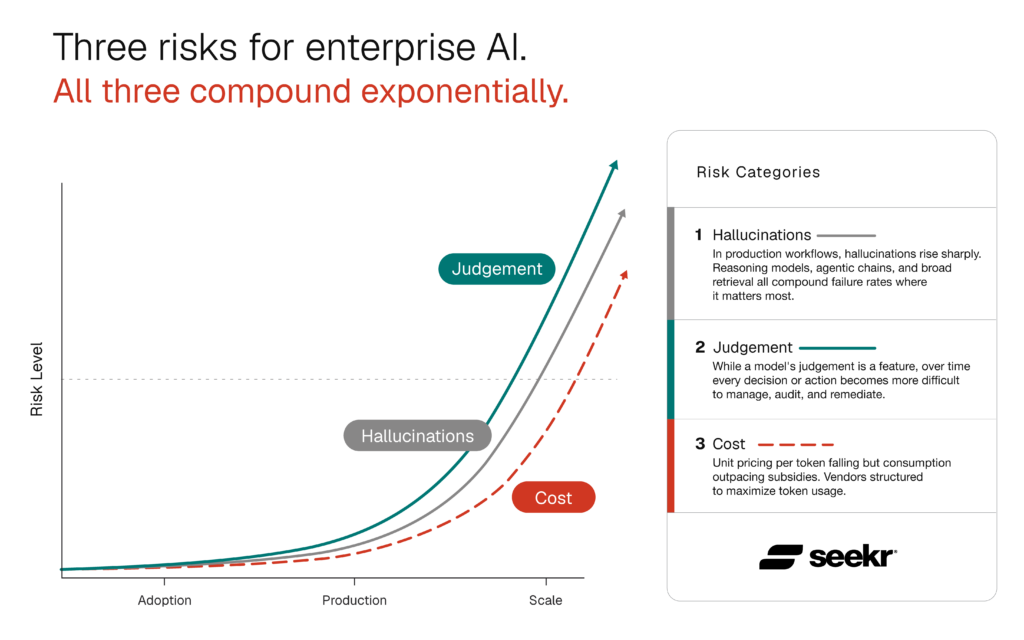
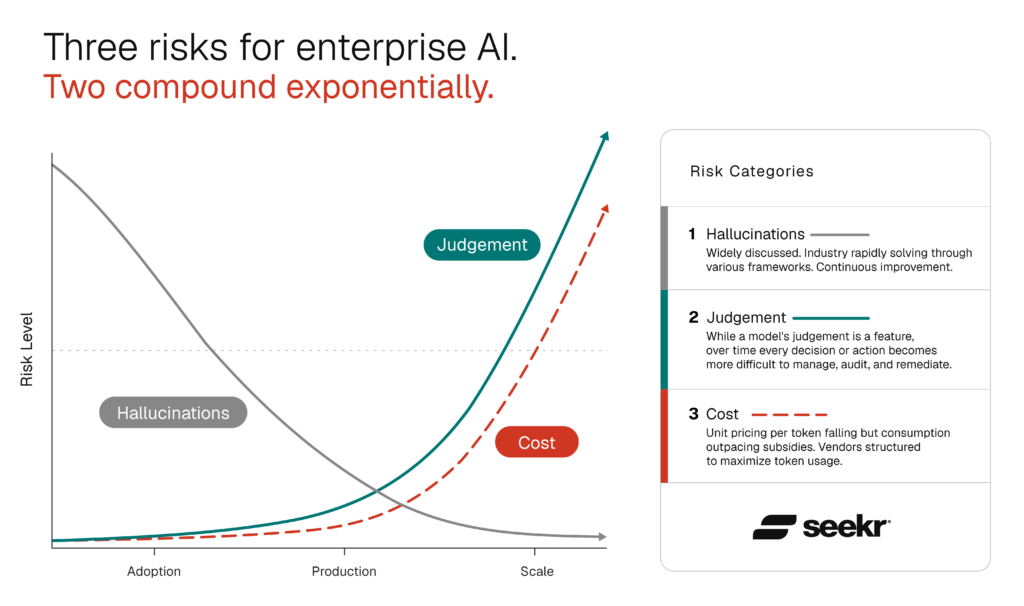
The lever is the same: system-level explainability across every influence on every output. It is the only one that bends the cost curve and the hallucination curve together. It is the only one that lets operators stay accountable for AI outputs at the scale enterprises are now pushing without giving up their trust boundary.
If you are spending real money on enterprise AI in 2026, you should know what fraction of that spend produced source-backed, explainable, defensible work inside your own trust boundary. If you cannot answer that question, the spend is unmanaged.
Stop paying for confidently wrong answers
Wrong answers cost the same as right ones. Remove the hallucination tax with AI you can explain from the start.
Score your AI spend

FAQs
The industry says hallucinations are decreasing. What’s different about your view?
The aggregate is decreasing on isolated tasks like summarization. In the workflows enterprises actually run — agentic chains, reasoning over broad retrieval, high-stakes domains — hallucinations are increasing. OpenAI’s own system cards show their newest reasoning models hallucinating two to three times more than their predecessors. Stanford has measured 69–88% hallucination on specific legal queries. We follow the workflow data, not the benchmark data.
Isn’t this just RAG (Retrieval Augmented Generation)?
RAG is a retrieval pattern. SeekrFlow is a source-control architecture. The difference is that SeekrFlow surfaces, scores, and lets you dial back the specific sources behind every output — at the token level — without retraining. Most RAG implementations cannot tell you why a specific output landed where it did. SeekrFlow can.
What’s the ROI?
Two ways to measure. First: cost per defensible output — the fraction of your AI spend that produced auditable, source-grounded answers. We typically move that number from undefined to measurable to optimized. Second: time-to-production for regulated AI applications. Customers like Arcas use us to ship sovereign AI under EU AI Act constraints that frontier-model-only stacks cannot meet.
Does this work with our existing model provider?
Yes. SeekrFlow is model-agnostic. You can bring your own fine-tuned model or use open-source. The control plane sits on top. We coexist with the major frontier providers; we are not a replacement for them.
How is this different from observability or eval platforms?
Observability tells you what happened. Eval tells you whether it was right or wrong. Neither lets you intervene at the source. SeekrFlow does — operators can prune sources, narrow retrieval scope, and re-fit principle alignment in production without retraining. The loop closes.
What about token cost?
Pruning low-value sources reduces hallucinations and reduces the tokens spent producing them. Both lines bend down together. We don’t promise lower per-token cost. We promise more defensible output per dollar.
Where do you fit in regulated and sovereign environments?
Built for them. SeekrFlow is deployable on customer infrastructure (private cloud, sovereign cloud, on-prem) and ships with the data attribution and context attribution frameworks needed to meet EU AI Act, OMB M-25-21, and analog federal directives. Provenance is a first-class output.
How does this compare to Palantir AIP and its Ontology approach?
Different question, different answer. Palantir grounds the LLM in a structured ontology — a software model of your enterprise’s operational data. That works well for structured operational queries (supply chain, fleet, logistics) and requires significant upfront investment to build. SeekrFlow operates at a different layer. We let operators see, score, and tune the Q&A pairs and source documents behind every model output — including any ontology that’s been built. Most enterprise AI workflows reason over unstructured content (documents, transcripts, regulations) where ontology grounding has limited reach. Source-level control covers both. The two approaches can coexist; the lift to deploy Seekr is days, not quarters.



Accelerate your path to AI impact
Book a consultation with an AI expert. We’re here to help you speed up your time to AI ROI.
Request a demo
